问题场景
工作中遇到Excel中有两列数据,其中有重复的,需要去除重复数据,得到一个没有重复数据的数据列。
方案
方案1:遍历某一列的各项,去和另一列每一项对比。
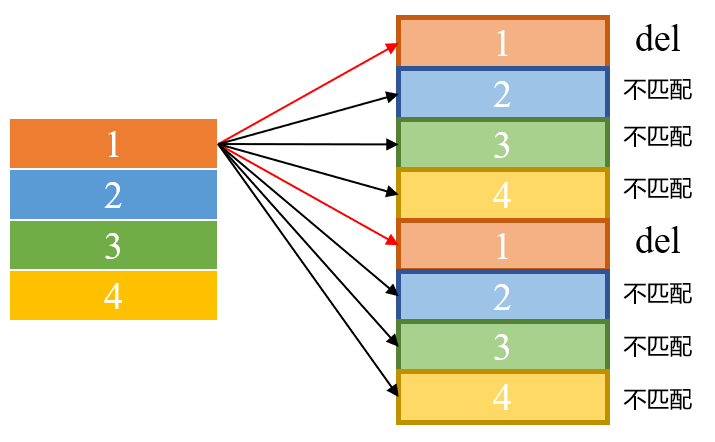
方案2:两列分别按某种顺序排列,之后以某列为标准,每一项对照另一列,依次找出重复项。
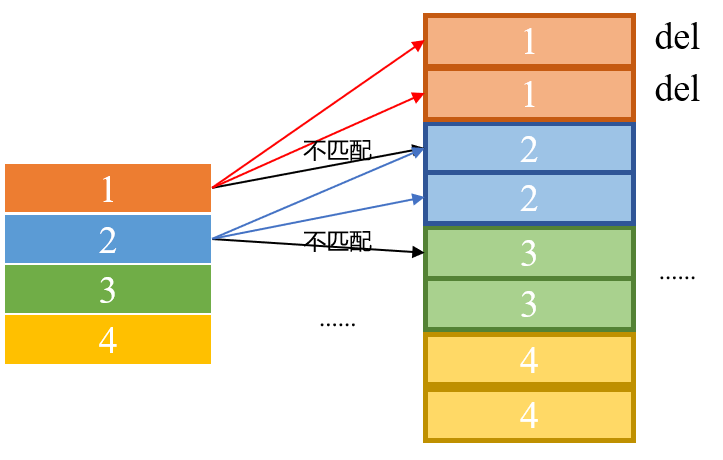
方案3:直接将两列合为一列,排序后依次遍历,去除重复的即可。
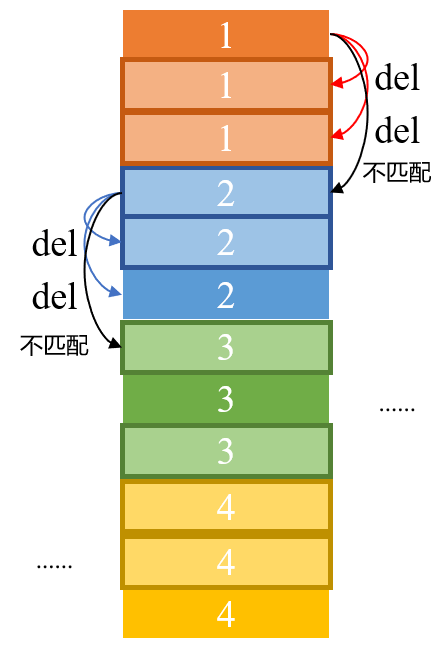
思考
不同的方案所用的时间复杂度不同:
方案一O(mn),m、n分别为两列数据的条数;
方案二O((n1+1)+(n2+1)+(n3+1)+…),n1、n2分别为右列中与左列某一项相同的数据条数;
方案三O(m+n-1),m、n分别为两列数据的条数;
方案一明显复杂度更高,方案二与方案三则取决于m、n的大小;但在实际使用(excel操作)中,明显方案三更为方便。
遇到这个问题时,我的第一反应是方案二,同事一位老大哥则是提出了方案三,不得不说老哥还是更有经验。这事里也意识到日常工作中的常见问题也可能蕴含了算法思想,一方面要能够找到效率更高的方法,另一方面实际操作的体验也是需要注意的。